你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何将聊天完成 API 与部署在 Azure AI Foundry 模型中 的多模式 模型配合使用。 除了文本输入之外,多模式模型还可以接受其他输入类型,例如图像或音频输入。
先决条件
若要在应用程序中使用聊天补全模型,需要:
一份 Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读 从 GitHub 模型升级到 Azure AI Foundry 模型 。
Azure AI Foundry 资源(以前称为 Azure AI 服务)。 有关详细信息,请参阅 创建 Azure AI Foundry 资源。
终结点 URL 和密钥。


请使用以下命令安装适用于 Python 的 Azure AI 推理包:
pip install -U azure-ai-inference
具有聊天补全模型部署,并支持音频和图像。 如果没有,请参阅 “添加和配置 Foundry 模型 ”,将聊天完成模型添加到资源。
- 本文使用的是
Phi-4-multimodal-instruct。
- 本文使用的是
使用聊天补全
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/api/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="Phi-4-multimodal-instruct"
)
如果已使用 Microsoft Entra ID 支持配置资源,则可以使用以下代码片段创建客户端。
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/api/models",
credential=DefaultAzureCredential(),
model="Phi-4-multimodal-instruct"
)
使用包含图像的聊天补全
某些模型可以跨文本和图像进行推理,并根据这两种输入生成文本补全。 在本部分中,你将以聊天的方式探索一些用于视觉的模型的功能。
可以使用 URL 将图像传递给模型,并将其包含在具有角色 用户的消息中。 还可以使用 数据 URL ,以便将文件的实际内容嵌入到以字符串编码的 base64 URL 中。
我们来看看可从 此源下载的下图:
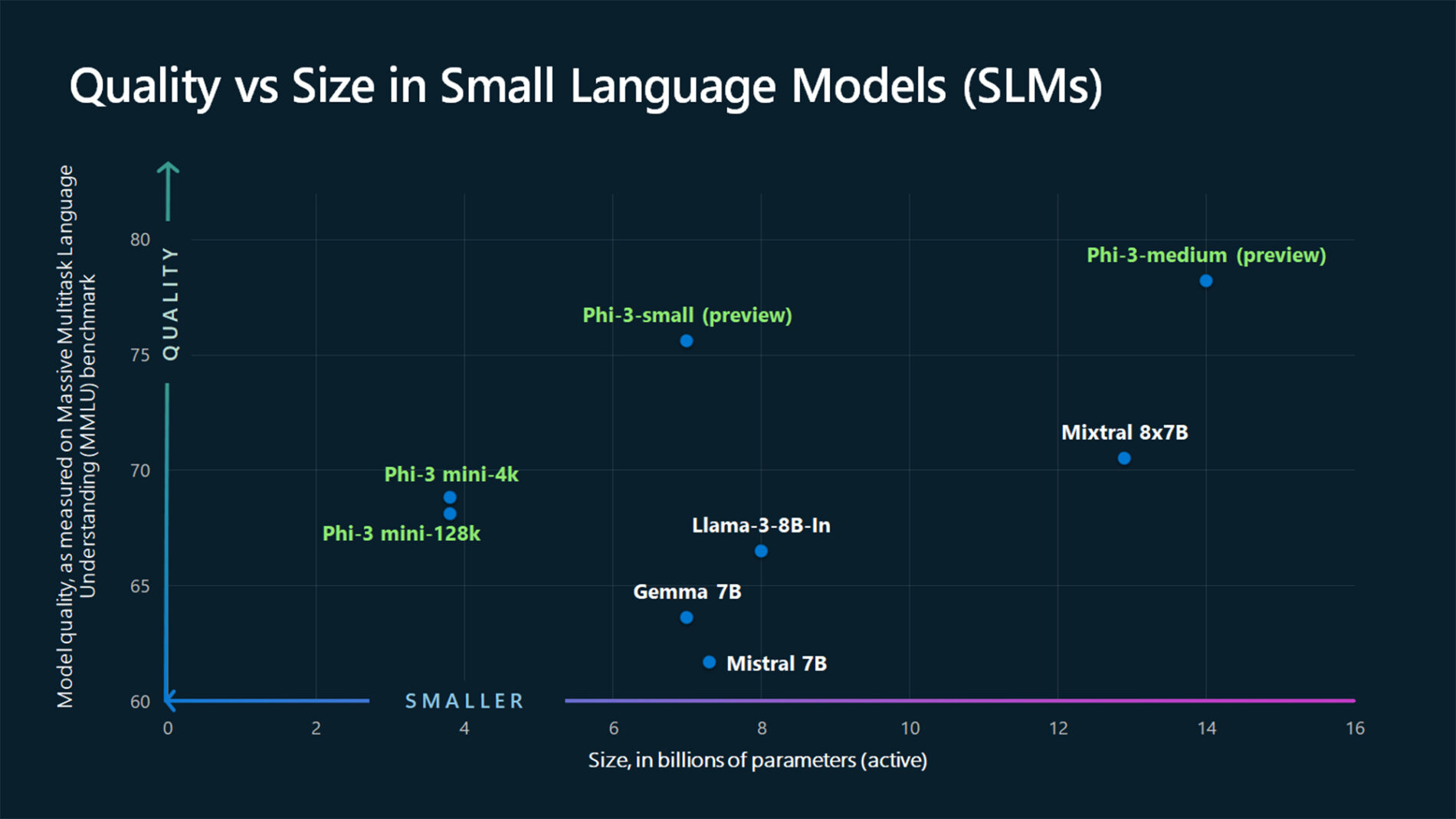{kind=link}

可以将图像加载到 数据 URL 中,如下所示:
from azure.ai.inference.models import ImageContentItem, ImageUrl
data_url = ImageUrl.load(
image_file="The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg",
image_format="jpeg"
)
数据 URL 的格式为 data:image/{image_format};base64,{image_data_base64}。
现在,创建包含图像的聊天补全请求:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image_url=data_url)
]),
],
temperature=1,
max_tokens=2048,
)
响应如下所示,可从中查看模型的使用统计信息:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-4-omni
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
用法
图像分为令牌并提交到模型进行处理。 在涉及图像时,这些标记通常被称为图像块。 每个模型可能会将给定图像分解为不同数量的块。 阅读模型卡以了解详细信息。
多回合对话
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。 阅读模型卡以了解每个模型的情况。
图像 URL
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 此方法要求 URL 为公共 URL,且不需要特定处理。
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image_url=ImageUrl(image_url))
]),
],
temperature=1,
max_tokens=2048,
)
使用包含音频的聊天补全
某些模型可以跨文本和音频输入进行推理。 以下示例演示如何将音频上下文发送到还支持音频的聊天完成模型。 使用 InputAudio 将音频文件的内容加载到数据包中。 内容被编码到 base64 数据并通过载荷发送。
from azure.ai.inference.models import (
TextContentItem,
AudioContentItem,
InputAudio,
AudioContentFormat,
)
response = client.complete(
messages=[
SystemMessage("You are an AI assistant for translating and transcribing audio clips."),
UserMessage(
[
TextContentItem(text="Please translate this audio snippet to spanish."),
AudioContentItem(
input_audio=InputAudio.load(
audio_file="hello_how_are_you.mp3", audio_format=AudioContentFormat.MP3
)
),
],
),
],
)
响应如下所示,可从中查看模型的使用统计信息:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 Python SDK 不提供直接方法来实现,但可以按照以下方法表示有效负载:
response = client.complete(
{
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3"
}
}
]
},
],
}
)
用法
音频分为令牌,并提交到模型进行处理。 某些模型可能直接在音频令牌上运行,而其他模型可能使用内部模块执行语音转文本,从而产生不同的计算令牌策略。 阅读模型卡,了解每个模型工作方式的详细信息。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何将聊天完成 API 与部署在 Azure AI Foundry 模型中 的多模式 模型配合使用。 除了文本输入之外,多模式模型还可以接受其他输入类型,例如图像或音频输入。
先决条件
若要在应用程序中使用聊天补全模型,需要:
一份 Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读 从 GitHub 模型升级到 Azure AI Foundry 模型 。
Azure AI Foundry 资源(以前称为 Azure AI 服务)。 有关详细信息,请参阅 创建 Azure AI Foundry 资源。
终结点 URL 和密钥。
使用以下命令安装适用于 JavaScript 的 Azure 推理库:
npm install @azure-rest/ai-inference npm install @azure/core-auth npm install @azure/identity如果使用 Node.js,则可以在 package.json中配置依赖项:
package.json
{ "name": "main_app", "version": "1.0.0", "description": "", "main": "app.js", "type": "module", "dependencies": { "@azure-rest/ai-inference": "1.0.0-beta.6", "@azure/core-auth": "1.9.0", "@azure/core-sse": "2.2.0", "@azure/identity": "4.8.0" } }导入以下内容:
import ModelClient from "@azure-rest/ai-inference"; import { isUnexpected } from "@azure-rest/ai-inference"; import { createSseStream } from "@azure/core-sse"; import { AzureKeyCredential } from "@azure/core-auth"; import { DefaultAzureCredential } from "@azure/identity";
具有聊天补全模型部署,并支持音频和图像。 如果没有,请参阅 “添加和配置 Foundry 模型 ”,将聊天完成模型添加到资源。
- 本文使用的是
Phi-4-multimodal-instruct。
- 本文使用的是
使用聊天补全
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
const client = ModelClient(
"https://<resource>.services.ai.azure.com/api/models",
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
如果已使用 Microsoft Entra ID 支持配置资源,则可以使用以下代码片段创建客户端。
const clientOptions = { credentials: { "https://cognitiveservices.azure.com" } };
const client = ModelClient(
"https://<resource>.services.ai.azure.com/api/models",
new DefaultAzureCredential()
clientOptions,
);
使用包含图像的聊天补全
某些模型可以跨文本和图像进行推理,并根据这两种输入生成文本补全。 在本部分中,你将以聊天的方式探索一些用于视觉的模型的功能。
重要
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。
若要查看此功能,请下载图像并将信息编码为 base64 字符串。 生成的数据应位于数据 URL 内:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
可视化图像:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
现在,创建包含图像的聊天补全请求:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
model: "Phi-4-multimodal-instruct",
}
});
响应如下所示,可从中查看模型的使用统计信息:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
用法
图像分为令牌并提交到模型进行处理。 在涉及图像时,这些标记通常被称为图像块。 每个模型可能会将给定图像分解为不同数量的块。 阅读模型卡以了解详细信息。
多回合对话
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。 阅读模型卡以了解每个模型的情况。
图像 URL
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 此方法要求 URL 为公共 URL,且不需要特定处理。
使用包含音频的聊天补全
某些模型可以跨文本和音频输入进行推理。 以下示例演示如何将音频上下文发送到还支持音频的聊天完成模型。
在此示例中,我们将创建一个函数 getAudioData 来加载数据中 base64 编码的音频文件的内容,因为模型需要它。
import fs from "node:fs";
/**
* Get the Base 64 data of an audio file.
* @param {string} audioFile - The path to the image file.
* @returns {string} Base64 data of the audio.
*/
function getAudioData(audioFile: string): string {
try {
const audioBuffer = fs.readFileSync(audioFile);
return audioBuffer.toString("base64");
} catch (error) {
console.error(`Could not read '${audioFile}'.`);
console.error("Set the correct path to the audio file before running this sample.");
process.exit(1);
}
}
现在,让我们使用此函数来加载存储在磁盘上的音频文件的内容。 我们会在用户消息中发送音频文件的内容。 请注意,在请求中,我们还指示音频内容的格式:
const audioFilePath = "hello_how_are_you.mp3"
const audioFormat = "mp3"
const audioData = getAudioData(audioFilePath);
const systemMessage = { role: "system", content: "You are an AI assistant for translating and transcribing audio clips." };
const audioMessage = {
role: "user",
content: [
{ type: "text", text: "Translate this audio snippet to spanish."},
{ type: "input_audio",
input_audio: {
audioData,
audioFormat,
},
},
]
};
const response = await client.path("/chat/completions").post({
body: {
messages: [
systemMessage,
audioMessage
],
model: "Phi-4-multimodal-instruct",
},
});
响应如下所示,可从中查看模型的使用统计信息:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 Python SDK 不提供直接方法来实现,但可以按照以下方法表示有效负载:
const systemMessage = { role: "system", content: "You are a helpful assistant." };
const audioMessage = {
role: "user",
content: [
{ type: "text", text: "Transcribe this audio."},
{ type: "audio_url",
audio_url: {
url: "https://example.com/audio.mp3",
},
},
]
};
const response = await client.path("/chat/completions").post({
body: {
messages: [
systemMessage,
audioMessage
],
model: "Phi-4-multimodal-instruct",
},
});
用法
音频分为令牌,并提交到模型进行处理。 某些模型可能直接在音频令牌上运行,而其他模型可能使用内部模块执行语音转文本,从而产生不同的计算令牌策略。 阅读模型卡,了解每个模型工作方式的详细信息。
本文介绍如何将聊天完成 API 与部署在 Azure AI Foundry 模型中 的多模式 模型配合使用。 除了文本输入之外,多模式模型还可以接受其他输入类型,例如图像或音频输入。
先决条件
若要在应用程序中使用聊天补全模型,需要:
一份 Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读 从 GitHub 模型升级到 Azure AI Foundry 模型 。
Azure AI Foundry 资源(以前称为 Azure AI 服务)。 有关详细信息,请参阅 创建 Azure AI Foundry 资源。
终结点 URL 和密钥。
将 Azure AI 推理包添加到项目:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.4</version> </dependency>如果使用 Entra ID,则还需要以下包:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.15.3</version> </dependency>导入下列命名空间:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.ChatCompletionsClient; import com.azure.ai.inference.ChatCompletionsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.ai.inference.models.ChatCompletions; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
聊天补全模型部署。 如果您没有,请阅读 添加并配置 Foundry 模型 以向您的资源添加聊天完成模型。
- 此示例使用
phi-4-multimodal-instruct。
- 此示例使用
使用聊天补全
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
ChatCompletionsClient client = new ChatCompletionsClientBuilder()
.credential(new AzureKeyCredential("{key}"))
.endpoint("https://<resource>.services.ai.azure.com/api/models")
.buildClient();
如果已使用 Microsoft Entra ID 支持配置资源,则可以使用以下代码片段创建客户端。
TokenCredential defaultCredential = new DefaultAzureCredentialBuilder().build();
ChatCompletionsClient client = new ChatCompletionsClientBuilder()
.credential(defaultCredential)
.endpoint("https://<resource>.services.ai.azure.com/api/models")
.buildClient();
使用包含图像的聊天补全
某些模型可以跨文本和图像进行推理,并根据这两种输入生成文本补全。 在本部分中,你将以聊天的方式探索一些用于视觉的模型的功能:
若要查看此功能,请下载图像并将信息编码为 base64 字符串。 生成的数据应位于数据 URL 内:
Path testFilePath = Paths.get("small-language-models-chart-example.jpg");
String imageFormat = "jpg";
可视化图像:
现在,创建包含图像的聊天补全请求:
List<ChatMessageContentItem> contentItems = new ArrayList<>();
contentItems.add(new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"));
contentItems.add(new ChatMessageImageContentItem(testFilePath, imageFormat));
List<ChatRequestMessage> chatMessages = new ArrayList<>();
chatMessages.add(new ChatRequestSystemMessage("You are an AI assistant that helps people find information."));
chatMessages.add(ChatRequestUserMessage.fromContentItems(contentItems));
ChatCompletionsOptions options = new ChatCompletionsOptions(chatMessages);
options.setModel("phi-4-multimodal-instruct")
ChatCompletions response = client.complete(options);
响应如下所示,可从中查看模型的使用统计信息:
System.out.println("Response: " + response.getValue().getChoices().get(0).getMessage().getContent());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
用法
图像分为令牌并提交到模型进行处理。 在涉及图像时,这些标记通常被称为图像块。 每个模型可能会将给定图像分解为不同数量的块。 阅读模型卡以了解详细信息。
多回合对话
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。 阅读模型卡以了解每个模型的情况。
图像 URL
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 此方法要求 URL 为公共 URL,且不需要特定处理。
Path testFilePath = Paths.get("https://.../small-language-models-chart-example.jpg");
List<ChatMessageContentItem> contentItems = new ArrayList<>();
contentItems.add(new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"));
contentItems.add(new ChatMessageImageContentItem(
new ChatMessageImageUrl(testFilePath)));
List<ChatRequestMessage> chatMessages = new ArrayList<>();
chatMessages.add(new ChatRequestSystemMessage("You are an AI assistant that helps people find information."));
chatMessages.add(ChatRequestUserMessage.fromContentItems(contentItems));
ChatCompletionsOptions options = new ChatCompletionsOptions(chatMessages);
options.setModel("phi-4-multimodal-instruct")
ChatCompletions response = client.complete(options);
使用包含音频的聊天补全
某些模型可以跨文本和音频输入进行推理。 此功能在适用于 Java 的 Azure AI 推理包中不可用。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何将聊天完成 API 与部署在 Azure AI Foundry 模型中 的多模式 模型配合使用。 除了文本输入之外,多模式模型还可以接受其他输入类型,例如图像或音频输入。
先决条件
若要在应用程序中使用聊天补全模型,需要:
一份 Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读 从 GitHub 模型升级到 Azure AI Foundry 模型 。
Azure AI Foundry 资源(以前称为 Azure AI 服务)。 有关详细信息,请参阅 创建 Azure AI Foundry 资源。
终结点 URL 和密钥。
请使用以下命令安装 Azure AI 推理包:
dotnet add package Azure.AI.Inference --prerelease如果使用 Entra ID,则还需要以下包:
dotnet add package Azure.Identity
聊天补全模型部署。 如果没有,请阅读 添加和配置 Foundry 模型 以将聊天完成模型添加到您的资源中。
- 此示例使用
phi-4-multimodal-instruct。
- 此示例使用
使用聊天补全
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/api/models"),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
如果已使用 Microsoft Entra ID 支持配置资源,则可以使用以下代码片段创建客户端。
client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/api/models"),
new DefaultAzureCredential(),
);
使用包含图像的聊天补全
某些模型可以跨文本和图像进行推理,并根据这两种输入生成文本补全。 在本部分中,你将以聊天的方式探索一些用于视觉的模型的功能:
重要
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。
若要查看此功能,请下载图像并将信息编码为 base64 字符串。 生成的数据应位于数据 URL 内:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
可视化图像:
现在,创建包含图像的聊天补全请求:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "Phi-4-multimodal-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
响应如下所示,可从中查看模型的使用统计信息:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
用法
图像分为令牌并提交到模型进行处理。 在涉及图像时,这些标记通常被称为图像块。 每个模型可能会将给定图像分解为不同数量的块。 阅读模型卡以了解详细信息。
多回合对话
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。 阅读模型卡以了解每个模型的情况。
图像 URL
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 此方法要求 URL 为公共 URL,且不需要特定处理。
使用包含音频的聊天补全
某些模型可以跨文本和音频输入进行推理。 以下示例演示如何将音频上下文发送到还支持音频的聊天完成模型。 使用 InputAudio 将音频文件的内容加载到数据包中。 内容被编码到 base64 数据并通过载荷发送。
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem("hello_how_are_you.mp3", AudioContentFormat.Mp3),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
响应如下所示,可从中查看模型的使用统计信息:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 Python SDK 不提供直接方法来实现,但可以按照以下方法表示有效负载:
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem(new Uri("https://.../hello_how_are_you.mp3"))),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
响应如下所示,可从中查看模型的使用统计信息:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
用法
音频分为令牌,并提交到模型进行处理。 某些模型可能直接在音频令牌上运行,而其他模型可能使用内部模块执行语音转文本,从而产生不同的计算令牌策略。 阅读模型卡,了解每个模型工作方式的详细信息。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何将聊天完成 API 与部署在 Azure AI Foundry 模型中 的多模式 模型配合使用。 除了文本输入之外,多模式模型还可以接受其他输入类型,例如图像或音频输入。
先决条件
若要在应用程序中使用聊天补全模型,需要:
一份 Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读 从 GitHub 模型升级到 Azure AI Foundry 模型 。
Azure AI Foundry 资源(以前称为 Azure AI 服务)。 有关详细信息,请参阅 创建 Azure AI Foundry 资源。
终结点 URL 和密钥。
聊天补全模型部署。 如果没有,请参阅 “添加和配置 Foundry 模型 ”,将聊天完成模型添加到资源。
- 本文使用的是
Phi-4-multimodal-instruct。
- 本文使用的是
使用聊天补全
若要使用聊天补全 API,请使用追加到基 URL 的路由 /chat/completions 以及 api-key 中指示的凭据。 Authorization 标头也支持 Bearer <key> 格式。
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
如果你已为资源配置了 Microsoft Entra ID 支持,请将你的令牌以 的格式放入 Authorization 标头中Bearer <token>。 使用范围 https://cognitiveservices.azure.com/.default。
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
使用 Microsoft Entra ID 可能需要资源中的额外配置才能授予访问权限。 了解如何 使用 Microsoft Entra ID 配置无密钥身份验证。
使用包含图像的聊天补全
某些模型可以跨文本和图像进行推理,并根据这两种输入生成文本补全。 在本部分中,你将以聊天的方式探索一些用于视觉的模型的功能:
重要
模型中的每个回合仅支持一个图像,并且只有最后一个图像保留在上下文中。 如果添加多个图像,则会导致错误。
若要查看此功能,请下载图像并将信息编码为 base64 字符串。 生成的数据应位于数据 URL 内:
小窍门
需要使用脚本或编程语言构造数据 URL。 本文使用 JPEG 格式的此示例图像。 数据 URL 的格式如下:data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ...。
{kind=link}
可视化图像:
现在,创建包含图像的聊天补全请求:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
响应如下所示,可从中查看模型的使用统计信息:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}
图像分为令牌并提交到模型进行处理。 在涉及图像时,这些标记通常被称为图像块。 每个模型可能会将给定图像分解为不同数量的块。 阅读模型卡以了解详细信息。
使用包含音频的聊天补全
某些模型可以跨文本和音频输入进行推理。 以下示例演示如何将音频上下文发送到还支持音频的聊天完成模型。
以下示例在聊天记录中发送了以 base64 数据编码的音频内容:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "input_audio",
"input_audio": {
"data": "0xABCDFGHIJKLMNOPQRSTUVWXYZ...",
"format": "mp3"
}
}
]
}
],
}
响应如下所示,可从中查看模型的使用统计信息:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
模型可以通过将 URL 作为输入传递,从 可访问的云位置 读取内容。 您可以按如下方式指定有效负载:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3",
}
}
]
}
],
}
响应如下所示,可从中查看模型的使用统计信息:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
音频分为令牌,并提交到模型进行处理。 某些模型可能直接在音频令牌上运行,而另一些模型可能使用内部模块执行语音转文本,从而产生不同的计算令牌策略。 阅读模型卡,了解每个模型工作方式的详细信息。