你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure AI 搜索支持将数据导入搜索索引的两种基本方法:以编程方式将数据推送到索引中,或通过将 Azure AI 搜索索引器指向支持的数据源来拉取数据。
本教程介绍了如何使用推送模型通过分批处理请求并使用指数回退重试策略来高效地为数据编制索引。 你可以下载并运行示例应用程序。 本教程还介绍了应用程序的关键方面以及索引数据时要考虑的因素。
在本教程中,你将使用适用于 .NET 的 Azure SDK 中的 C# 和 Azure.Search.Documents 库 来:
- 创建索引
- 测试各种批大小以确定最高效的大小
- 以异步方式索引批
- 使用多个线程以提高索引编制速度
- 使用指数退避重试策略重试失败的文档
先决条件
- 拥有有效订阅的 Azure 帐户。 免费创建帐户。
- Visual Studio。
下载文件
本教程的源代码位于 Azure-Samples/azure-search-dotnet-scale GitHub 存储库的 optimize-data-indexing/v11 文件夹中。
重要注意事项
以下因素会影响索引编制速度。 有关详细信息,请参阅 索引大型数据集。
- 服务层级和分区/副本数:添加分区或升级层级会提高索引编制速度。
- 索引架构复杂性:添加字段和字段属性会降低索引编制速度。 索引越小,索引速度越快。
- 批大小:最佳批大小因索引架构和数据集而异。
- 线程数/工作器数:单个线程不能充分利用索引编制速度。
- 重试策略:指数退避重试策略是优化索引的最佳做法。
- 网络数据传输速度:数据传输速度可能是一个限制因素。 从 Azure 环境中为数据编制索引可以提高数据传输速度。
创建 Azure AI 搜索服务
本教程需要可在 Azure 门户中创建的 Azure AI 搜索服务。 还可以在当前订阅中找到 现有服务 。 为了准确测试和优化索引速度,我们建议使用生产环境中计划使用的同一层。
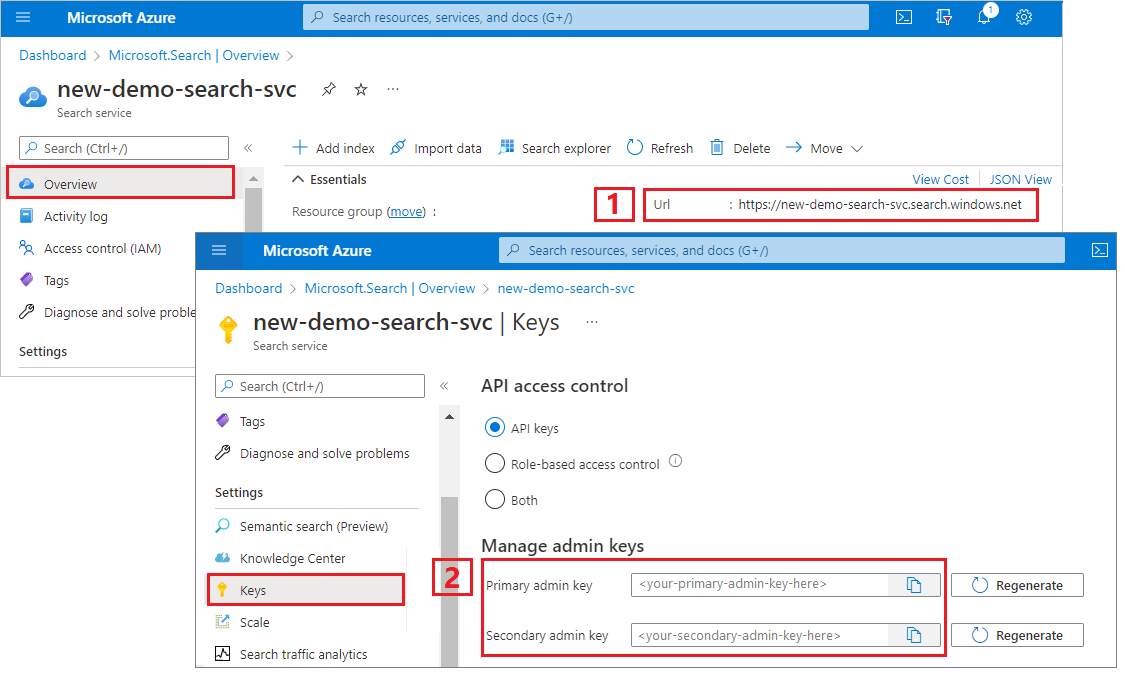
获取 Azure AI 搜索的管理密钥和 URL
此教程使用基于密钥的身份验证。 复制管理员 API 密钥以粘贴到 appsettings.json 文件中。
登录到 Azure 门户。 在服务 概述 页上,复制终结点 URL。 示例终结点可能类似于
https://mydemo.search.windows.net。在“设置密钥”>上,获取服务完全权限的管理密钥。 有两个可交换的管理员密钥,为保证业务连续性而提供,以防需要滚动一个密钥。 可以在请求中使用主要或辅助密钥来添加、修改和删除对象。
配置你的环境
启动 Visual Studio 并打开“OptimizeDataIndexing.sln”。
在解决方案资源管理器中,打开“appsettings.json”以提供该服务的连接信息。
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
浏览代码
更新appsettings.json后,OptimizeDataIndexing.sln中的示例程序应准备好生成并运行。
此代码派生自快速入门的 C# 部分 :使用 Azure SDK 进行全文搜索,该 SDK 提供有关使用 .NET SDK 的基础知识的详细信息。
此简单的 C#/.NET 控制台应用程序执行以下任务:
- 基于 C#
Hotel类(此类还引用Address类)的数据结构创建新索引 - 测试各种批大小以确定最高效的大小
- 以异步方式为数据编制索引
- 使用多个线程以提高索引编制速度
- 使用指数回退重试策略重试失败的项
运行该程序之前,请抽时间研究此示例的代码和索引定义。 相关代码存在于多个文件中:
- Hotel.cs 和 Address.cs 包含用于定义索引的架构
- DataGenerator.cs 包含一个简单的类,可轻松创建大量的酒店数据
- ExponentialBackoff.cs 包含用于优化索引编制过程的代码,如此文章中所述
- Program.cs 包含用于创建和删除 Azure AI 搜索索引、为各批数据编制索引以及测试不同批大小的函数
创建索引
此示例程序使用 Azure SDK for .NET 来定义和创建 Azure AI 搜索索引。 它利用 FieldBuilder 类,从 C# 数据模型类来生成索引结构。
数据模型由 Hotel 类定义,该类还包含对 Address 类的引用。 FieldBuilder 向下钻取多个类定义,以生成索引的复杂数据结构。 元数据标记用于定义每个字段的属性,例如字段是否可搜索或可排序。
Hotel.cs文件中的以下代码片段指定单个字段和对另一个数据模型类的引用。
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
在 Program.cs 文件中,索引是使用由 方法生成的名称和字段集合来定义的,并按下示方法创建:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
生成数据
DataGenerator.cs 文件中实现了一个简单的类,该类可生成用于测试的数据。 这个课程的目的是简化生成大量文档的过程,使这些文档能够带有独特的 ID 以便于编制索引。
若要获取包含唯一 ID 的 100,000 家酒店的列表,请运行以下代码:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
在此示例中,有两种大小的酒店可用于测试:small 和 large。
索引的架构会影响索引编制速度。 完成本教程后,请考虑转换此类别以生成最符合预期索引架构的数据。
测试批大小
若要将单个或多个文档加载到索引中,Azure AI 搜索支持以下 API:
分批为文档编制索引可显著提高索引编制性能。 这些批最多可以是 1,000 个文档,每个批最多可以 16 MB。
确定数据的最佳批大小是优化索引编制速度的关键。 影响最佳批大小的两个主要因素是:
- 索引的架构
- 数据的大小
由于最佳批大小取决于索引和数据,因此最佳方法是测试不同的批大小,以确定方案索引速度最快的结果。
以下函数演示了一种用于测试批大小的简单方法。
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
因为并非所有文档都大小相同(尽管本示例中如此),所以我们要估计发送到搜索服务的数据的大小。 可以使用以下函数执行此作,该函数首先将对象转换为 JSON,然后确定其大小(以字节为单位)。 利用此技术,我们可以根据 MB/秒的索引编制速度来确定哪些批大小是最高效的。
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
此函数需要一个 SearchClient 以及要为每个批大小测试的尝试次数。 由于每个批次的索引编制时间可能会有一些变化,因此默认情况下会将每个批次尝试三次,以使结果更具统计意义。
await TestBatchSizesAsync(searchClient, numTries: 3);
运行函数时,控制台中应会显示类似于以下示例的输出:

确定哪个批大小最有效,并在本教程的下一步中使用该批大小。 你可能会发现不同批大小的索引编制速度(MB/秒)差异不大。
为数据编制索引
现在你确定了要使用的批大小,下一步就是开始为数据编制索引。 为了高效地为数据编制索引,此示例:
- 使用了多个线程/工作器
- 实现了指数回退重试策略
取消第 41 行至第 49 行的注释,然后重新运行程序。 在此运行过程中,示例会生成并发送批文档,如果在不更改参数的情况下运行代码,最多 100,000 个文档。
使用多个线程/工作器
若要利用 Azure AI 搜索的索引速度,请使用多个线程同时向服务发送批处理索引请求。
一些 关键注意事项 可能会影响最佳线程数。 你可以修改此示例并测试不同的线程数,以确定适合你的方案的最佳线程数。 但是,只要有多个线程并发运行,就应该能够利用大部分提升的效率。
当你增加命中搜索服务的请求时,可能会遇到表示请求没有完全成功的 HTTP 状态代码。 在编制索引期间,有两个常见的 HTTP 状态代码:
- 503 服务不可用:此错误表示系统负载过重,当前无法处理请求。
- 207 多状态:此错误意味着某些文档成功,但至少一个文档失败。
实现指数回退重试策略
如果发生故障,则应使用 指数退避重试策略重试请求。
Azure AI 搜索的 .NET SDK 会自动重试 503s 和其他失败的请求,但应实现自己的逻辑来重试 207s。 像 Polly 这样的开源工具在重试策略中非常有用。
在此示例中,我们实现了自己的指数回退重试策略。 我们首先定义一些变量,包括maxRetryAttempts和用于失败请求的初始delay。
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
索引操作的结果存储在变量 IndexDocumentResult result 中。 此变量允许检查批处理中的文档是否失败,如以下示例所示。 如果发生部分失败,将基于失败的文档 ID 创建新的批。
RequestFailedException 还应捕获异常,因为它们表示请求完全失败,需要重新尝试。
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
在这里,将指数退避代码包装到一个函数中,以便可以轻松调用它。
然后创建另一个函数来管理活动线程。 为简单起见,此处未包括该函数,但你可在 ExponentialBackoff.cs 中找到该函数。 可以使用以下命令调用函数,其中 hotels 要上传 1000 的数据是批大小,是 8 并发线程数。
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
运行函数时,应会看到类似于以下示例的输出:

当一批文档处理失败时,会显示错误信息,指示失败,并且表明正在重新尝试处理该批文档。
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
函数运行完毕后,可以验证是否已将所有文档添加到索引中。
浏览索引
程序运行完成后,可以通过编程方式或使用 Azure 门户中的 搜索资源管理器 浏览填充的搜索索引。
采用编程方式
可以使用两个主要选项来检查索引中的文档数:对文档计数 API 和获取索引统计信息 API。 这两个路径都需要处理时间,因此,如果返回的文档数量最初低于预期,请不要惊慌。
计数文档
Count Documents操作用于检索搜索索引中的文档数量。
long indexDocCount = await searchClient.GetDocumentCountAsync();
获取索引统计信息
“获取索引统计信息”操作会返回当前索引的文档计数以及存储使用情况。 索引统计信息的更新时间比文档计数长。
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure 门户
在 Azure 门户中的左窗格中,在“索引”列表中找到优化索引索引。

文档计数和存储大小基于获取索引统计信息 API,可能需要几分钟才能更新。
重置并重新运行
在开发的前期试验阶段,设计迭代的最实用方法是,删除 Azure AI 搜索中的对象,并允许代码重新生成它们。 资源名称是唯一的。 删除某个对象后,可以使用相同的名称重新创建它。
本教程的示例代码会检查现有索引并将其删除,使你能够重新运行代码。
还可以使用 Azure 门户来删除索引。
清理资源
在自己的订阅中操作时,最好在项目结束时删除不再需要的资源。 持续运行资源可能会产生费用。 可以逐个删除资源,也可以删除资源组以删除整个资源集。
可以使用左侧导航窗格中的“所有资源”或“资源组”链接在 Azure 门户中查找和管理资源。
下一步
若要详细了解如何为大量数据编制索引,请尝试以下教程: