Utente:Pracchia-78/AWB/Registro

Dal 2008 mi occupo di correzioni di errori sulle voci di Wikipedia tramite il browser del sistema operativo del mio PC; dalla metà del 2010 suddivido i miei contributi con un editor semiautomatico, AWB nella versione 5.2.0.0, che mi permette di eseguire operazioni altrimenti impossibili con il solo browser e con concreti risultati[1].
In questa pagina si trova un test (seguìto da altri) condotto con AWB nella versione 5.3.1.0[2]: lo scopo è un tentativo di quantificare la probabile percentuale di errori ortografici, di refusi e di formattazione presenti nelle pagine principali, cioè nelle voci dell'enciclopedia utilizzando specifiche condizioni di ricerca degli stessi. È annessa una descrizione a titolo di promemoria attinente al tipo di errori di cui mi occupo.
Se altri Utenti hanno esperienze simili sono grato se me le comunicheranno in questa pagina
Generazione della lista
Tramite AWB ho selezionato l'opzione che permette di cercare con criterio casuale dieci voci nell'enciclopedia. Cliccando ripetutamente su make list ho ottenuto una lista[3] di 2 000 voci accessibile tramite questo collegamento. La lista è stata subito salvata sul mio pc con la formattazione tipica di Wikipedia, in un file nominato Random.txt.
Dal campo Souce dal menu a discesa ho scelto Text file: (UTF-8) e per sincerarmi che non vi fossero errori ho caricato di nuovo in memoria il contenuto del Random.txt previa cancellazione della lista poco prima generata da AWB.
Elaborazione della lista
Per l'elaborazione ho seguito la consueta procedura standard caricando prima di tutto i Typos presenti sul server di Wikimedia tramite caricamento del file settings.xml (contenente le regex e la lista dei Find and replace) per infine interrogare il server con le mie credenziali (nome utente e password) sul progetto it.wikipedia). Una volta accettato, AWB ha iniziato a caricare in memoria il contenuto del primo elemento della lista.
Particolarità emerse durante il lavoro
La lista di lavoro mi offriva pagine in NS-0 nelle quali non era possibile né stabilire né intuire a priori quali tipi di errori ortografici, refusi o di formattazione avrei trovato per il semplice motivo che la lista era stata generata con criterio casuale da AWB tramite una serie di interrogazioni al database di it.wikipedia.[4]. Tuttavia visto l'elevato numero di voci contenute nella lista e la generosa dimensione del mio settings.xml, vi era fin da principio l'assoluta garanzia di trovare un generico lavoro per AWB e per di più quantitativamente interessante.[5].
La fase di sostituzione delle parole errate, di correzione di template e delle entity si è svolta nel rispetto dell'attuale policy d'uso prevista per le utenze prive di flag e, per quanto attiene l'aspetto tecnico, senza che il software si "congelasse" nel caricare in memoria o salvare una specifica voce[6]. Le sostituzioni sono andate tutte a buon fine e l'occasione mi ha offerto la possibilità di affinare il file settings.xml perché si erano manifestate un paio di eccezioni (difficilissime da prevedere senza una reale manovra "sul campo", cioè in NS-0, di AWB). L'incidenza dei falsi positivi è stata lievemente minore di quella che mi sarei atteso e ciò ha influito positivamente sul regolare svolgimento del lavoro. Preciso che non sono mai uscito da AWB per eseguire correzioni "extra" a mano al di fuori del counter di AWB per cui il numero di effettivi interventi è realmente quello verso il fondo della lista archiviata.
Gli errori
Dove si trovano
Una certo quantitativo di errori è presente nelle pagine di Wikipedia in funzione di alcuni fattori:
- è in numero alto dove il numero di parole contenute è elevato e contemporaneamente è basso il numero di modifiche che le pagine hanno subito nel corso del tempo a partire dalla loro creazione
- è in numero alto dove è basso il numero delle utenze singole che vi hanno lavorato e con lunghi intervalli di tempo fra le singole modifiche
- è in numero alto dove scarseggia il controllo (patrolling) contro i vandalismi o le modifiche errate
- è in numero più alto dove è minore l'aggiornamento delle pagine e in quelle trascurate per qualsivoglia motivazione[7].
Può formarsi una interdipendenza fra il primo punto e quelli successivi perché una pagina con molte parole e pochi aggiornamenti eseguiti da pochi singoli utenti e a lunghi intervalli di tempo presenta maggiori probabilità di vari errori (e non solo di tipo ortografico) di un'altra attentamente seguita, costantemente aggiornata, modificata e tenuta sotto un buon controllo da vari utenti.
Ne consegue che, in prima approssimazione, sono le pagine delle voci (nonché le relative pagine di discussione) quelle in cui avrò maggior occasione di riscontrare un interessante numero di errori: senza contare che attualmente (aprile 2012) l'enciclopedia conta circa 910 000 voci.
Ricordo che una parte consistente di errori deve obbligatoriamente essere registrata anche nel file settings.xml di AWB perché possano essere "scoperti"[8].
Come si intercettano
Perché taluni presunti errori acquisiscano lo status di "autentici errori" occorre una discussione seguita da un consenso della comunità wikipediana. Fin qui nihil sub sole novum. Il problema è che i dizionari e le grammatiche e la stessa Accademia della Crusca ai quali volgiamo l'attenzione, non sono entità normative il cui dettato abbia valore legale e nemmeno, più semplicemente, fonti normative sempre pacificamente accettate dagli studiosi. Sto pensando a una analogia con le norme tecnico scientifiche fissate dal SI e che sono quotidianamente disattese talora anche in contesti educativi (libri di testo e dispense) o informativi (quotidiani, stampa periodica "generalista" o specializzata) o economici (fatture commerciali di enti erogatori di servizi) nonostante i vari Stati contraenti ne abbiano sancito in modo inequivocabile il suo uso (anche al di fuori dall'ambito tecnico-scientifico) e il suo abuso con tanto di sanzioni.
Quindi, sotto questo aspetto, la soluzione che da i suddetti testimoni "cartacei o elettronici" potrebbe provenirci si limita ad essere, più modestamente, un suggerimento da analizzare e discutere fra noi utenti. È un fatto certo che i grammatici e i compilatori di dizionari sovente non spiegano quale variante grafica sia da preferirsi e la Crusca si limita ad analizzare, giustificare e spiegare quale sia la ragion d'essere di una variante nel corso del tempo ma senza prendere una netta posizione al riguardo[9]. Le regole grammaticali, dovrebbe essere un fatto di indubitabilità storica, non sono ferree: penso, per esempio, che non vi è un accordo unanime fra gli studiosi a riguardo della D eufonica[10] e con variegati pareri anche su Wikipedia[11] e che il filosofo Ugo Dèttore in tutti i suoi scritti usava a esempio al posto del più comune ad esempio o del più classico "per esempio". È verosimile che il suo gusto personale o un particolare modo d'intendere l'eufonia, prevalessero su regole cristallizzate. Se a ciò aggiungiamo che non è chiaro se una determinata parola che è entrata nel dizionario sia di uso comune e comprensibile per tutti o la stragrande parte degli italoparlanti ce n'è a sufficienza per aprire una discussione su come ci si debba regolare ortograficamente nella stesura delle voci.
Il consenso
Può capitare che, durante lo svolgersi delle discussioni, le parti contendenti adducano razionali motivazioni che potrebbero equamente essere candidate come regola (policy) da seguire. Dal momento che la regola è, o dovrebbe essere, per quanto possibile una sola, breve e chiara, in tali situazioni di equità nei giudizi espressi è accaduto con una certa frequenza che le risoluzioni finali si fondassero su questi punti:
- Non vietare in assoluto una certa grafia in quanto essa può essere una legittima e libera scelta stilistica del singolo autore
- Consigliare in generale di preferire la forma più comune della parola (o della locuzione), ovvero quella più usata perché maggiormente comprensibile ai lettori / alle lettrici dell'enciclopedia
- Fare un uso omogeneo delle varianti ortografiche all'interno della singola voce
- Dare la preferenza a quella forma ortografica che al momento è la più utilizzata all'interno di una o più categorie.
Alcuni paradossi. La "Regolaccia" delle tre generazioni
La fretta di correggere
Nel correggere gli errori di ortografia e i refusi dattilografici non ci vuole fretta!
A volte può essere utile gettare un'occhiata preliminare al periodo precedente o a quello seguente per rendersi conto che, benché in presenza di marchiani errori da "matita blu", c'è dell'altro. C'è la sintassi da sistemare, un periodo oscuro, alcune frasi sconclusionate nella sezione precedente, magari anche un vandalismo dissimulato (e, se siamo dentro i tempi, ricordarsi poi di avvisare l'utenza), ecc., ecc. In pratica potrebbe capitare (è accaduto e ancora accadrà) di correggere invano un errore ortografico all'interno di un periodo che in primis richiedeva una rielaborazione della sintassi.
Non bisogna avere fretta di correggere!
AWB è anche un browser con il quale è possibile ispezionare il testo andando con l'occhio sulle e al di là delle fasce di testo colorate. In varie occasioni ho scoperto nuovi errori di scrittura che non erano presenti nel dizionario e né nella pagina degli errori, presenza di frasi banali, di assurdità di ogni genere e addirittura vandalismi passati inosservati.
La velocità e il rendimento
Riporto, modificando un po' le parole ma non il senso, due distinti commenti di altrettante utenze a proposito degli attuali limiti di AWB (aprile 2012) ai quali devono soggiacere le utenze che non operano come bot ufficiali.
Per la frustrazione che si potrebbe provare, ho già specificato le ragioni per le quali la fretta non paga. Non entro poi nel merito se sia più frustrante attendere un minuto fra una modifica e l'altra, oppure sentirsi dire alla fine del lavoro che si son fatte una serie di modifiche da annullare per questo o per quel motivo...
Più interessante è l'obiezione dell'Anonimo 1 in quanto reitera un luogo comune, un tranello. La velocità slegata da un parametro non dice nulla. La velocità di intervento la si misura sia come quantità di correzioni all'interno di una singola voce eseguite tramite un automatismo rapportate a quella che un utente di media esperienza potrebbe eseguire tramite il suo browser nel medesimo tempo impiegato dall'automatismo (A) e sia come quantità intercorrente fra le correzioni massime presumibili di un utente di media esperienza nell'unità di tempo (di solito si assume come riferimento il minuto oppure l'ora) e quelle di un bot (2). Nelle due illustrazioni che ho preso a mo' di esempio si palesa che AWB, a differenza di un utente umano, può svolgere correzioni di ragguardevole imponenza. Soprattutto la figura (A) mostra e dimostra che in una manciata di minuti (3-4 al massimo) si possono eseguire all'interno di 2-3 voci ben oltre 1 000 correzioni, senza infrangere la policy!
{kind=link}
{kind=link}
Occorre inoltre prudenza perché un massiccio numero di piccole modifiche a brevi intervalli di tempo, anche se eseguite a mano, non è generalmente ben visto dalla comunità di Wikipedia in particolar modo di chi si occupa di patrolling (e dal buon senso). Faccio un esempio pratico. Se devo cercare tutte le occorrenze di perchè e poi di poichè, poi di benchè, poi di (...) è inutile e dispendioso in termini di tempo (mio e altrui) e risorse di rete che le faccia e le rifaccia per ogni parola; meglio una regex ad hoc da implementare in AWB. E se proprio non posso o non voglio usare AWB, mi vengono in aiuto i correttori ortografici di cui i maggiori browser sono forniti o installabili come plugin e poi inserire nel campo della ricerca hè, oltre che osservare le sottolineature rosse.
Accuratezza, aritmomania, errori, fretta
Si tratta di inquadrare al più presto che cosa abbia a che spartire l'aritmomania nel presente contesto. Mi viene in aiuto un saggio redatto dai colleghi di lingua inglese leggibile qui.
In linea generale potrebbe essere utile controllare il numero dei propri contributi a scadenze temporali ben definite (per es. a inizio e fine sessione) specie se si è versati nella statistica. Per esempio si può conoscere tramite una semplice differenza aritmetica quanti edit ho compiuto correggendo una parola errata e vedere come tale errore si ripresenta in termini quantitativi nel corso del tempo senza bisogno di fare un esagerato numero di note al margine in questa pagina. Un po' di inventiva personale non guasta, anzi.
La situazione cambia e non di poco quando il conteggio degli edit è fine a sé stesso; ovvero quando è un'azione circoscritta in un esclusivo ammirare un contatore che gira, gira e gira... senza che chi l'osserva si renda conto che, a monte, ci sta un progetto a cui contribuisce e che per sua intrinseca caratteristica richiederà un costante aggiornamento del quale non si vede un termine!
Questa situazione non solo può minare la salute del singolo utente ma potrebbe anche arrecare danni al funzionamento dell'enciclopedia. Cosa capita quando un notevole quantitativo di utenti fanno un gran numero di modifiche di piccola entità a brevi intervalli di tempo? Sovraccaricano inutilmente i server con uno sperpero di risorse! Non è cosa da sottovalutare tant'è che esiste un apposito template che i patroller notificano nelle pagine di discussioni degli utenti: {{anteprima}} vale a dire un avviso di presunto abuso di salvataggi. Tuttavia queste sequenze di "salvataggi impulsivi" non vanno confuse con il vandalismo; è però bene che questi utenti si adeguino a usare l'anteprima.
(proseguirà...)
La torre di Babele e le tre generazioni
Le Odi barbare di Carducci e il Duca d'Atene di Tommaseo furono alcuni fra i tentativi che i letterati dell'Ottocento tentarono per ridare lustro alla poesia e alla prosa rifacendosi a modelli stilistici del passato. Il contenuto di queste opere è tutt'oggi (2012) comprensibile senza bisogno di particolari spiegazioni a un lettore di media preparazione scolastica. Furono tentativi che, però, fallirono perché la metrica e il lessico del tempo erano diretti ad altri modelli e innovazioni. Inoltre nel passaggio dal Settecento all'Ottocento si assistette in Europa alla nascita di nuove professioni e studi e, sopra di tutto, al progressivo allontanamento (specializzazione) fra le discipline umanistiche e quelle scientifiche (si pensi all'affermarsi del Positivismo) con la impellente necessità di "inventare" o "adattare" un lessico preesistente in altre lingue per le sopravvenute necessità.
Verso la fine del XX secolo una pubblicazione periodica italiana ad amplissima diffusione, propagandava la commercializzazione a dispense della Divina commedia precisando che era stata tradotta (sic) in italiano; alcuni anni dopo alcuni insegnanti delle scuole medie osservavano che il Verga non poteva essere proposto in lettura agli studenti di lingua italiana dell'Alto Adige perché essi non capivano il senso delle frasi, il quale doveva essere costantemente tradotto (sic) in classe dai docenti.
Preferisco esentarmi dai commenti perché io e tu che leggi questa righe possiamo trarne alcuni liberi spunti di riflessione riferiti al contesto wikipediano. Un contesto quanto mai variegato e mutevole per i liberi apporti di conoscenza che utenti volontari sparsi per il mondo apportano costantemente.
Più che risposte preferisco propormi alcune situazioni tratte dalla quotidianità.
È il contenuto di Wikipedia comprensibile a tutti? Se qualcuno desidera espandere il proprio orizzonte cognitivo su determinati argomenti nei quali è versato ma non si è tenuto aggiornato nel corso di alcuni anni, vi riuscirà leggendo i "nostri" articoli? Se il quidam assumesse l'essenza di Tre distinte generazioni quale sarà il grado di fruibilità dei contenuti di Wikipedia? Il contenuto di Wikipedia risponde alla domanda culturale delle Tre generazioni? Il contenuto di Wikipedia è curato, è oggetto di attenzione come il contenitore nell'equo rispetto delle Tre generazioni?[12]. La lingua impiegata nelle voci nella sua complessiva morfologia è senza dubbio adeguata per essere compresa senza o minime difficoltà dalle Tre generazioni?
Alle scuole elementari avevo un maestro che in previsione di sorbirci i nostri temi scalcagnati d'italiano aveva l'abitudine di ripeterci: «Quando scrivete fate finta che io non conosca affatto l'argomento e non entrate d'un subito in medias res» Ripeteva che suo padre (anch'egli maestro) gli aveva insegnato il latinorum «a forza di calci nel sedere (sic).» e pure noi ci dovevamo avvezzare. Alle locuzioni latine. Senza bisogno ogni volta di "reinventare la ruota" è auspicabile (anzi necessario) che le composizioni, ivi compresa una enciclopedia, siano presentate con un vestito che le renda degne per lo meno sotto l'aspetto della comprensibilità delle parole-concetti esposte.
Ancora. Mi interrogo se sia una scelta oculata quella di dare per scontato che sia sempre un bene che a ogni battito di ciglia il lettore / la lettrice debba distrarre la lettura dell'articolo di proprio interesse da un link che tenta di spiegare un termine, una locuzione, un modo di dire? Come si comporterà, cosa penserà se egli/ella non trovando un link esplicativo di un termine non italiano consulterà un dizionario che -massima sfortuna- non elenca proprio quell'eccezione o pur elencandola non riesce a dare un senso compiuto alla frase che leggeva[13]? Vero è che ogni lettore/lettrice può, è liberissimo di approfondire o di ignorare ciò che nel testo reputa più utile o inutile ai propri interessi; ma in tante voci si possono riscontrare link al limite del ridicolo e non solo per la loro ripetitività all'interno del medesimo testo[14]
Mi domando se le scelte tecniche operate a monte del Progetto tengano conto che vi sono persone, vi sono nazioni povere, molto povere che utilizzano sistemi operativi e browser vetusti e che non gliene importa un fico secco se "Zilla" o "Plorer" sia o no il migliore o peggiore browser in circolazione.
Mi domando se il software di Wikipedia sia da noi usato dando la massima priorità all'igiene dell'occhio. Perché, a quanto pare, i testi li si leggono con gli occhi i quali, a differenza di un PC, non possono essere regalati, acquistati o sostituiti una volta deteriorati.
Mi domando se stiamo fornendo (o siamo sulla buona strada per farlo) la possibilità anche ai ciechi e ai sordi di fruire dell'enciclopedia: qual è, a tal proposito, lo stato di interesse e l'avanzamento dei lavori della Wikipedia parlata?
Errare humanum est
Premesso che gli errori ortografici non sono vandalismi (esclusi quei casi dove l'errore è intenzionale in quanto utilizzato con la palese intenzione di danneggiare l'enciclopedia); è un obbligo che chi corregge mantenga un rapporto di cordialità e indulgenza nei confronti di chi ha sbagliato l'ortografia e la grammatica. Mai far pesare l'errore per mezzo di parole esplicite ma nemmeno presentandoli con più o meno velati sarcasmi alludenti all'autore e alle sue capacità.
Resta il fatto che alcuni di noi potrebbero avere sviluppata una personale reazione repulsiva alla presenza di un testo con errori d'ortografia o grammaticali: in ogni caso non si deve mai toccare la buona fede di chi li ha commessi. Sarà invece più saggio che l'utente che vuol correggere indirizzi i propri sforzi su come l'errore potrebbe essere concretamente contrastato con il minor impiego di tempo e fatica.
Grazie al controllo discreto che eseguo sugli errori ho per esempio notato delle peculiarità fra le quali una certa ciclicità nel loro ripresentarsi dovuta a varie cause -non tutte chiarite- che qui è fuori luogo enunciare. Grazie però a tali periodiche ricorrenze mi è possibile programmare un certo ordine di intervento prioritario in rapporto alla loro maggiore o minore diffusione nelle pagine di Wikipedia. Non nego che in tutto ciò possa entravi una personale (e forse innata) predisposizione a studiare le cause piuttosto che a deriderle (fatti salvi gli sporadicissimi casi in cui -del tutto involontariamente- si verifichino involontari e ameni giochi di parole che muovono l'ilarità generale compreso chi ha errato).
Il testo sotto riportato è parte del codice di condotta di chi lavora con un bot. L'originale è qui;
L'essenza resta intatta anche per quanti correggono gli errori "a mano".
Il colore e il grassetto sono miei.

Essere in grado di rispondere cordialmente, rapidamente e in maniera pertinente è una condizione importante per poter gestire un bot.
Sempre al fine di migliorare l'aspetto comunicativo è importante utilizzare oggetti delle modifiche chiari ed esplicativi.»
(proseguirà...)
Gli errori secondo AWB
Se opportunamente istruito AWB gestisce e ripara (ovvero: sostituisce) quasi tutti i tipi di errori di ortografia, di refusi e dattilografici tipici della scrittura con tastiera, ma anche i regionalismi o parole dialettali in contesti che non li prevedono affatto. Nel contempo AWB esamina anche gli errori di formattazione per esempio da <i> </i> a '' '' comprese le eccedenze o la scarsità di spaziatura interlinea ("ritorni di carrello"). Su quest'ultimo caso specificherò in una sezione a parte se e come convenga operare in presenza di correzioni di minore entità (minor edits).
Il software AWB è anche in grado di svolgere altri compiti qui non trattati ma comunque descritti nel manuale di istruzioni.
Il file settings.xml di AWB
Il file settings.xml contiene quelle impostazioni che servono al funzionamento del software su un progetto Wiki. A fianco di una struttura predefinita che permette un funzionamento di base, l'utente può inserire delle espressioni regolari che costituiscono il "dizionario interno" di AWB. Mi limito a un sunto delle possibilità che riguardano in modo specifico la ricerca degli errori nei testi.
La regex che segue, attinente alla formattazione in uso su Wikipedia, permette di trovare all'interno di una pagina tutte le occorrenze di </br> <br\> <br/> e di sostituirle in blocco con: <br />
<IRule xsi:type="Rule">
<enabled_>false</enabled_>
<Children />
<Name>Give <br /> tags proper XHTML format.</Name>
<ruletype_>OnWholePage</ruletype_>
<replace_></?br\s*/?></replace_>
<with_><br /></with_>
<ifContains_ />
<ifNotContains_ />
<regex_>true</regex_>
<ifIsRegex_>false</ifIsRegex_>
<numoftimes_>1</numoftimes_>
<ifRegexOptions_>None</ifRegexOptions_>
<regexOptions_>IgnoreCase</regexOptions_>
</IRule>
<IRule xsi:type="Rule">
<enabled_>false</enabled_>
<Children />
Esiste la possibilità di creare regex più complesse facenti uso di strutture annidate. Ma, al tempo stesso, è possibile scrivere regole strutturalmente più semplici e veloci (per lo meno dal punto di vista dell'operatore) ma che comunque richiedono attenzione per non provocare falsi positivi. Quella che segue cerca tutte le occorrenze di milano sostituendole con Milano
<Replacement>
<Find>\ milano</Find>
<Replace> Milano</Replace>
<Comment />
<IsRegex>false</IsRegex>
<Enabled>true</Enabled>
<Minor>false</Minor>
<BeforeOrAfter>false</BeforeOrAfter>
<RegularExpressionOptions>IgnoreCase</RegularExpressionOptions>
</Replacement>
I falsi positivi si possono sperimentare se, per esempio nella parte
<Find>\ milano</Find>
<Replace> Milano</Replace>
si elimina lo spazio vuoto
<Find>\milano</Find>
<Replace>Milano</Replace>
la regola cercherà non solo il singolo milano ma anche tutte le parole contenenti ...milano.... Per cui milano e assimilano, Assimilano verranno sostituite da Milano e da assiMilano, AssiMilano.
Potrebbero presentarsi situazioni nelle quali AWB porge una errata correzione nonostante l'operatore ritenga di aver posto la massima diligenza nello specificare i Find and replace. È quanto mi capitò nel passato in cui il wikilink di s.l.m. e varianti grafiche, anziché [[s.l.m]] veniva scritto in alcuni casi: [[[[s.l.m.]]]], cioè con ben quattro parentesi quadre al posto delle canoniche due. Il fatto mi apparì curioso in quanto non mi ritenevo in grado di replicare l'errore tramite un test a parte. Si esamini l'attuale struttura (alla data del 11 aprile 2012):
<Replacement>
<Find>slm</Find>
<Replace>s.l.m.</Replace>
<Comment />
<IsRegex>false</IsRegex>
<Enabled>true</Enabled>
<Minor>false</Minor>
<BeforeOrAfter>false</BeforeOrAfter>
<RegularExpressionOptions>None</RegularExpressionOptions>
</Replacement>
<Replacement>
<Find>s\.l\.m\.</Find>
<Replace>s.l.m.</Replace>
<Comment>After fixes!!</Comment>
<IsRegex>false</IsRegex>
<Enabled>true</Enabled>
<Minor>false</Minor>
<BeforeOrAfter>true</BeforeOrAfter>
<RegularExpressionOptions>None</RegularExpressionOptions>
</Replacement>
<Replacement>
<Find>s\.\ l\.\ m\.</Find>
<Replace>s.l.m</Replace>
<Comment />
<IsRegex>false</IsRegex>
<Enabled>true</Enabled>
<Minor>false</Minor>
<BeforeOrAfter>false</BeforeOrAfter>
<RegularExpressionOptions>None</RegularExpressionOptions>
</Replacement>
Dovetti controllare il contenuto della voce; riscontrato che s.l.m prendeva effettivamente più varianti grafiche all'interno della voce a causa dell'arbitrio dei collaboratori, dovetti stabilire un ordine di intervento, cioè una condizione supplementare alla regola, questa:
......
<Replacement>
<Find>s\.l\.m\.</Find>
<Replace>s.l.m.</Replace>
<Comment>After fixes!!</Comment> *mio commento*
<IsRegex>false</IsRegex>
<Enabled>true</Enabled>
<Minor>false</Minor>
<BeforeOrAfter>true</BeforeOrAfter> *condizione necessaria (true)*
......
in pratica la regola sopra riportata dev'essere applicata da AWB dopo le altre se si vuole che, in tutti i casi, si abbia la seguente resa grafica finale: s.l.m e non [[s.l.m.]].
Ecco un'altra sostituzione la quale ha richiesto che tutti i casi di sostituzione "del Sc --> dello Sc" abbiano attivata (true) la condizione <BeforeOrAfter>true</BeforeOrAfter> onde evitare questa falsa correzione "--> dello Scoialismo".
In questo altro caso è stato necessario applicare la correzione .d -> . D dopo la seguente correzione: della c.d. -> della cosiddetta altrimenti si sarebbe erroneamente corretto: della c. D.. Si consulti il Manuale di stile nel punto dove invita a ridurre al meno possibile le abbreviazioni al fine di una migliore leggibilità dei testi.
Ciò che è importante ricordare da queste situazioni è che una prova condotta nelle sotto pagine dell'utente non potrà mai sostituire un'esperienza reale "sul campo" cioè in NS:0. Attenzione! Non è detto che gli inconvenienti si manifestino "alla prima uscita", a volte occorrono giorni, a volte settimane per rendersi conto che qualcosa non va nel dizionario. Sotto questo aspetto la conduzione semiautomatica di AWB (cioè con ispezione umana prima del salvataggio) è raccomandabile anche ai botolatori con flag.
Le correzioni di minore entità con AWB
AWB è un software che "dialoga" con un server dedicato con un carico di esercizio, a volte intenso, il quale è bene che sia finalizzato a modifiche di indubbia utilità e urgenza. Viene pertanto logico domandarmi se le piccole modifiche (aggiustamenti di spaziatura fra le singole lettere o le righe, uniformazione di tag per compatibilità XHTML, rimozione di tag deprecati perché obsoleti o in contrasto con le norme di accessibilità e così via) abbiano le carte in regola per essere elaborate senza tema di essere additato come utente "sprecone di risorse"[15]. Dico che una risposta la potrei dare solo tramite un ragionamento ad inversum. Provo idealmente (voglio dire che non lo faccio materialmente ma solo ipoteticamente) a scartare sempre le predette correzioni di "minor conto" e come me tutti coloro che fanno uso di automatismi. Trascorso un congruo periodo di tempo -difficile da indicare ma senza dubbio reale- i testi in NS:0 mostreranno un incremento di più o meno piccoli "difetti di varia formattazione" al punto che ci potrebbero essere le condizioni per parlare di un intervento tramite bot. Dunque come potrei comportarmi? La soluzione che mi pare più ragionevole è quella di evitare i due precedenti "scenari" tramite una "diluizione", ovvero un inframmezzamento di consistenti correzioni con altre di minore entità specie se queste ultime sono di una certa rilevanza numerica nella pagina che sto per salvare.
Il campo oggetto scritto da AWB
L'operatore / l'operatrice può modificare, entro certi limiti, il contenuto del campo oggetto per adeguarlo alla lingua del Progetto oppure per indicare esattamente il compito che sta svolgendo.
Da tale contenuto si posso evincere alcune informazioni. Non mi risulta che la delucidazione che segue sia riscontrabile nel manuale tecnico di AWB. L'ho ricavata da mie osservazioni.
- Il campo oggetto è totalmente vuoto
- chi manovra ha il flag di bot, ha volontariamente abilitato l'opzione Suppress "using AWB" in edit summary e ha apportato modifiche a mano nell'edit box.
- Nel campo oggetto si legge solo la frase: using AWB (usando AWB)
- chi manovra ha disabilitato l'opzione Add replacements to the edit summary oppure ha scritto a mano nell'edit box ovvero tutt'e due i casi.
- AWB ha letto e applicato unicamente le regex accessibili dalla scheda Options, Advanced settings
- AWB ha applicato una o più regole di sola formattazione mentre il manovratore non ha compilato il campo oggetto
- Nel campo oggetto si legge replaced: abbile → abile, (sostituzione)
- AWB ha applicato la regola inserita nel file settings.xml
- Nel campo oggetto si legge typos fixed: inghilterra → Inghilterra, (correzioni tipografiche)
- AWB ha applicato la regola inserita nella pagina dei Typos
- Nel campo oggetto si legge removed: stocazz, (rimozione)
- AWB ha applicato la regola inserita nel file settings.xml
A seconda di come è configurato, AWB può scrivere più combinazioni nel campo oggetto fino al numero massimo di caratteri permesso.
I numeri racchiusi fra parentesi tonde, nell'esempio l' → l' (17) e un' → un' (2), indicano quante volte è stata applicata la sostituzione.
Impostazioni predefinite del campo oggetto
Quelle che seguono sono le impostazioni già presenti in AWB per il campo oggetto. Alcuni link sono rossi perché puntano a pagine di servizio e template presenti solo nella versione inglese di Wikipedia.
<SelectedSummary> </SelectedSummary>
<Summaries>
<string>clean up</string>
<string>re-categorisation per CFD</string>
<string>clean up and re-categorisation per CFD</string>
<string>removing category per CFD</string>
<string>subst:'ing</string>
<string>stub sorting</string>
<string>Typo fixing</string>
<string>bad link repair</string>
<string>Fixing links to disambiguation pages</string>
<string>Unicodifying</string>
Si noti che la parte di codice:
<SelectedSummary> </SelectedSummary>
serve a ricordare ad AWB che, all'avvio, deve predisporre uno (1) spazio vuoto nel campo oggetto. È necessario inserire nel campo oggetto almeno uno spazio, altrimenti AWB si rifiuta di lavorare.
L'impostazione di uno spazio vuoto nel campo oggetto è a discrezione dell'utente.
Personalmente l'ho trovato utile per risparmiare spazio in caso di lunghi elenchi di sostituzioni ma è ovvio che, per esigenze di servizio, potrebbe essere preferibile caricare all'avvio un'altra scelta. Durante il lavoro è sempre possibile cambiare i campi oggetto (o aggiungerne di nuovi e salvarli) selezionandoli dal menù a tendina Summary:... nella scheda Start.
Difetti noti o presunti di AWB
Se non diversamente specificato mi riferisco alla versione 5.3.1.0
- Non riconosce il template bio e aggiunge un ulteriore grassetto[16].
- In taluni casi non riesce a "vedere" in modo unitario (nella lista generata la pagina di servizio era ripetuta 4 volte).
Domande frequenti
La parola latta arrugginita.»
Questa è una sezione che serve in modo precipuo a quanti mi scriveranno facendomi notare che io avrei corretto un termine o una parte del discorso o applicata una formattazione in modo errato o per lo meno discutibile.
Premesso che nessuno è perfetto e appurata una certa ripetitività di contenuto nelle note lasciatemi da leggere (e da rispondere) in questi anni, per evitar(mi) uno spreco di tempo per fornire le (più o meno solite) spiegazioni, le riassumo qui sotto in termini generici.
- ...tramite AWB si può correggere la grammatica e la sintassi?
In teoria sì; in pratica è molto, molto difficile ottenere risultati soddisfacenti e applicabili su ampia scala.
- ...è vero che AWB è in grado di scoprire anche i vandalismi?
Sì ma a condizione che sia istruito per farlo.
- ...ho creato alcune pagine: posso usare AWB per correggerle oppure ci potresti pensare tu?
Se sei un utente registrato lo puoi fare benissimo tu.
- ...stai correggendo 18enne, 29enne, 41enne, ecc. in diciottenne, ventinovenne, ecc. Non si possono lasciarli così? Sono oltretutto anche più brevi!
No, il suffisso enne è errato perché è errato il modo usato per indicare una quantità numerica. Fra l'altro Wikipedia non è una tipografia editoriale o un magazine o la redazione di un Tiggì dove lo spazio e il tempo sono tiranni e la brevità un obbligo. Quelle che hai indicate ti informo che sono forme di scrittura errate stando alle norme legali internazionali. Trascendendo in errori: sono errate anche le forme 25nali, 25nnali, 25ennali e simili.
Quindi si deve scrivere: trentunenne e non 31enne, trentennali e non 30ennali, ecc. sempre che non siano citazioni testuali reperite al di fuori di Wikipedia e facilmente documentabili.
- "...se seguito da "stesso" e "medesimo" NON va accentato!''
Si tratta di una regola priva di fondamento e quel che è peggio è che a molti di noi è stata presentata sui banchi scolastici come norma inderogabile. Ti invito a leggere questa sezione sull'accento distintivo sui monosillabi e anche i collegamenti esterni.
Con l'occasione ti invito a controllare meglio il contenuto del campo oggetto delle mie modifiche (eseguite con l'aiuto di AWB) perché non viene corretto il pronome "se stessa/e/o/i" ma il pronome personale riflessivo di terza persona maschile e femminile singolare e plurale preceduto da una preposizione semplice. Esempio: di, a, da, in, con, su, per, fra, tra se (al posto del corretto sé) e AWB corregge solo in tale senso. Esempio: replaced: su se → su sé,.
- ...perché togli/aggiungi la "d" dopo la "A/a" e la "E/e"?
Per motivi d'eufonia. Consulta questa sezione. Se tuttavia la correzione tramite AWB avesse malauguratamente prodotto un accostamento cacofonico, ti prego di segnalarmi l'inconveniente tramite una differenza di versione scrivendo in quest'altra pagina. Grazie.
- ...credo che ormai [la parola] si può considerare entrata nell'uso comune italiano. Forse non si trova ancora in tutti i dizionari, ma [omissis] per ciò non ritengo la si debba scrivere in corsivo o tra virgolette...
La regola sulla grafia dei termini di origine non italiana è leggibile in questa sezione. Un approfondimento del corsivo è invece in questa pagina.
Per l'uso del corsivo estraggo questa parte:
Per capire in generale se una parola possa essere ritenuta italiana oppure no, basatevi sulle marche linguistiche presenti su un (buon) dizionario d'italiano, all'occorrenza anche più d'uno (ovviamente tenendo presenti le eccezioni su indicate).»
La questione consiste nello stabilire se:
- il termine è entrato nel lessico non specialistico quotidiano e
- se è comprensibile per tutti.
Considera che non è obbligatorio per un (buon) vocabolarista fare precedere studi statistici sulla penetrazione di un termine non italiano prima della compilazione di un (buon) dizionario e, d'altra parte, non possiamo farli noi o basarci su mere supposizioni su "sentito dire" o su un "mi pare". Sempre dalla policy estraggo:
Per dirimere concretamente la questione è opportuno stabilire prima di tutto se:
- non ho tenuto conto che su Wikipedia esisteva la corrispondente voce "esplicativa" (a prescindere che si trovi allo stato di abbozzo o già matura)
- in tale caso posso istruire AWB affinché aggiunga un wikilink "esplicativo" alle voci che ne sono prive.
- Ho tenuto conto che su Wikipedia non esiste un simile termine
- in tale caso sentiti-sentitevi libero-i di creare la voce; se essa continuerà a mancare e-o se sussistono dubbi sulla sua comprensione della popolazione italo-parlante, in tal caso è giustificato l'uso del corsivo.
- ...ti faccio notare che Look è una voce già presente in Wikipedia e trendy è oramai entrato nella lingua italiana. Perché li inserisci in corsivo?
Il motivo è semplice. Io leggo molto (anche) Wikipedia e il termine look l'ho scoperto utilizzato in una "marea" di accezioni, di significati che vanno molto ma molto al di là del contenuto leggibile nella voce: look. Lo vedo riferito a cose, animali e persone sia nella loro interezza che nelle loro rispettive particolarità, ivi compresi gli stati d'animo e i sentimenti e nei contesti più disparati. Evidentemente c'è qualcosa di indefinito e un'enciclopedia deve essere chiara quando espone i concetti. Quanti poi non conoscono l'inglese ne sapranno quanto prima leggendo look o look. Quindi ci sono due aspetti: chi ha scritto look doveva esplicitare (ma non l'ha fatto) e io non ho tempo per cercare i migliori significati di look. Altro non rimane che scriverlo in corsivo in attesa di una eliminazione dell'evasività del termine look. Idem per trendy.
- ...AWB sostituisce # con "numero" e "vs" con "contro": ti sei accorto che è scritto così anche sulla Wiki inglese?
I Paesi anglofoni usano quel sistema di notazione che però non è applicabile in italiano. Se spedisci una raccomandata in via Vattelapesca #154 o in: 154, via Vattelapesca, l'impiegato postale, magnanimo perché non la rifiuta, però te la correggerà con: via Vattelapesca, 154 oppure: n.154.
La policy applicata scrivendo su Wikipedia è in questa sezione dalla quale estraggo:
. Le uniche eccezioni sono rappresentate dalle citazioni verbatim e-o da trascrizioni di titoli di opere, di gare, di competizioni, di tornei.
- ...bene. Allora ti informo che # e "vs" fanno parte del titolo!
Oltre a non essere onniscente io non sono tenuto a conoscere se ciò a cui ti riferisci è un titolo originale o una libertà linguistica. AWB, nel rispetto generale della policy qui sopra indicata, deve correggere come ha fatto. Se è come tu dici, se ne sei più che sicuro, allora devi inserire nel titolo e solo nel titolo l'apposto template predisposto per impedirne la correzione da parte di bot.
- ...mi pare che qui non avresti dovuto correggere "rilasciare" con "concedere". Mi sembra eccessivo...
Ai miei tempi, nel Medioevo, esisteva ancora l'uso dei sinonimi. Oggigiorno lo snobismo anglomane, spacciato per innovazione e ricchezza stilistica, si espande a campi nei quali non v'è la benché minima necessità o convenienza di intendersi tramite l'impiego di un glossario tecnico anglosassone. Se qualcuno mi ha poi fatto notare che nel maggio 2012 avrei raggiunto centomila edit (ecchissenefr***) e se ciò corrispondesse a verità potrei dire qualcosa in merito ai mila e mila abusi di molti termini oramai omologati, appiattiti, cristallizzati, fossilizzati nel lessico italiese contemporaneo. La stragrande maggioranza dei termini da me osservati si possono ricondurre, in ossequio alla pigrizia mentale o a lacune scolastiche, a una pedestre traduzione o alla prima eccezione che si trova scritta nei dizionari bi-lingue.
Release è rilascio.
Ai miei remoti tempi un gas, una reazione termonucleare, uno pneumatico scoppiato, una bottiglia di spumante stappata, un profumo... emettevano, liberavano, sprigionavano, esalavano dei gas, rumori o altri accidenti. Oggi, sempre e unicamente, li rilasciano: (release). Gli Avvisi ai naviganti e il Meteomar non li si emettono, li si rilasciano (release). Un tempo la colonna di un film, un brano di un albumo, una versione di un software, un libro, venivano pubblicati.
Ora vengono rilasciati. Le release, appunto.
Il buffo è che per qualcuno l'adattamento al lessico italiano o addirittura la sua traduzione non esistono. La truaduzione (sic) di cover in italiano e'... cover! :P. Se non esiste la traduzione non si sa di ciò che stiamo parlando.
Avrai le mie scuse solo quando una persona fermata dalla Questura anzicché essere rilasciata, troverai da me "corretto": l'amica della portinaia, innocente, fu quasi subito pubblicata.
- ...ti faccio notare che qui [[link]] hai sbagliato perché hai sostituito cc con cm³ e 100Km con 100 km ma è proprio il nome del veicolo (auto, moto, ecc.), della categoria e della gara!
Sono addolorato della svista... ma non sono addentro agli eventi sportivi e non sono tenuto a conoscerli mentre siamo co-obbligati a rispettare queste norme legali.
Perciò, se sei assolutamente certo della grafia, ti prego di inserire l'apposito template per impedire che i bot correggano e che, se non lo conosci, ti comunicherò personalmente onde evitare abusi (nel presente contesto è fuori luogo).
- ...perché invece di usare AWB per questi non lo usi per correggere i veri errori?
AWB è un software che corregge in funzione del contenuto di questa pagina, mentre il file settings.xml una volta che è stato compilato, per esempio sul contenuto di quest'altra, applica ai testi dell'enciclopedia anche le sostituzioni indicate dall'operatore. Non entro nel merito di quali siano i veri errori di cui parli dal momento che la sola presenza/assenza nei dizionari (moderni) non sempre fornisce una risposta soddisfacente, vale a dire precisa. A proposito delle delle correzioni di minore entità potresti leggere le correzioni di minore entità e se hai suggerimenti, sentiti libero di scrivermi
- ...non capisco proprio la necessità che tu inserisca dal momento che il risultato grafico è immutato e il testo risultante in fase di editing mi confonde!
Hai le tue sacrosante ragioni (di mero carattere estetico) solo nell'ultima parte della domanda perché alcuni di noi preferiscono inserire al posto di il template {{TA|}}. Tale scelta mi riesce solo a mano, non con AWB. Personalmente la prediligo, a mano, solo in indicazioni abbastanza complesse come, per esempio: {{TA|15 218 218,37 m²}} invece di 15 218 218,37 m². Nota: entrambe le scritture porgono lo stesso risultato e sono accettate scrivendo su Wikipedia.
Hai invece semplicemente torto quando affermi che ...il risultato grafico è immutato.
Ti suggerisco di leggere Spazio unificatore, Hard space, Entità (markup) e se non ti rincresce di fare tu stesso delle prove pratiche per toccare con mano la differenza.
Se ti può interessare, ci sarebbero sono da correggere un sacco di scritture errate. Per indicare una distanza o un tempo o quello che si vuole, ci sono utenze che, sia pure in buona fede, fanno un uso errato delle convenzioni internazionali del SI. Cinque kilometri, cinque tonnellate, cinque minuti, cinque litri, ecc. sono, a volte, così scritti: 5k/Km, 5t, 5min, 5l invece di: 5 km, 5 t, 5 min, 5 l, ecc. Sotto tali premesse l'entità serve anche per scindere una parte numerica erroneamente attaccata senza soluzione di continuità al suo simbolo metrologico. Poniamo ora il caso (mica tanto ipotetico) che in 5km vi sia un errore nella quantità numerica la quale debba essere sostituita con 5,17. Cerchiamo di predire il comportamento di un contribuente ignaro delle norme SI. Si presume che da 5m si passi a leggere cosi: 5,17m. L'errore permane! Pertanto ho istruito AWB in modo che trovandosi in presenza di tali errori agisca come un "deterrente" per evitare futuri inserimenti di scritture non a norme SI e cioè separando la parte numerica dal simbolo letterale con uno spazio vuoto (non spezzabile!) tramite .
- ...sempre a proposito di spiegami questo: perché metti quell'entità in un elenco composto di righe di pochissimi caratteri?
Quando trovo le situazioni alle quali ti riferisci (e null'altro) salto a piè pari quella voce. Se dai un'occhiata alla differenza di versioni è quasi certo che il mio assistente (AWB) abbia trovato altre cose da sbrigare all'interno del testo oppure errori entrocontenuti proprio nelle righe brevi Ghz->GHz. Se il numero delle brevissime righe da spuntare che contengono eccede un certo quantitativo a me occorre un po' di tempo per deselezionarle a mano e così scade anche il tempo entro il quale il server attende una risposta da AWB. Quando il server comunica che AWB è fuori tempo, il risultato è che perdo tutto il lavoro fatto fino a quel punto su quella voce! Quindi, delle due l'una: o correggo tutto compreso gli errori ortografici, i refusi, la formattazione, ecc. oppure ignoro tutto. Cosa mi suggerite?
- ...perché togli <br /> e <small> </small>?
AWB, pur nei suoi limiti, si attiene all'usabilità del web. Quando incontra quel tag all'interno delle note e nelle didascalie li rimuove perché il carattere diventa troppo piccolo per essere di facile lettura. A volte è necessario che qualcuno (io) lo forzi a rimuovere anche all'interno del testo in quanto il suo impiego non è giustificato. Invece <small> non lo si rimuove dai template perché il suo uso è stato oggetto di un consenso comunitario.<br />
Per la rimozione di <br /> dai un'occhiata al termine del paragrafo qui sopra. Qualcuno ha richiesto di andare a capo e, a seguire, una interruzione di linea. È decisamente superfluo.
(proseguirà...)
Tabella di riepilogo
- Attenzione! Quando si parla di "voci" si intende sempre "lista di titoli di voci" non lista di contenuti! Se per esempio oggi compilo una lista e fra X giorni la ricarico in memoria, il contenuto che andrò a correggere è quello in essere alla data dell'operazione di correzione degli errori.
- Se non diversamente indicato la funzione utilizzata per la generazione delle liste in tabella è: Source:Random pages.
Dall'8 aprile 2012 ho iniziato a inserire nel mio file settings.xml alcuni errori di spaziatura fra le parole terminanti e inizianti con le vocali e separate da una virgola senza spazio a seguire (errore comune). Esempio: a,a --> a, a ------- i,e --> i, e[17].
- Alle liste generate con la funzione Wiki search: AWB applica alcune correzioni aggiuntive a quella indicata perché è configurato per scoprire il numero più elevato di errori e non il singolo errore.
- Dal 15 aprile 2012 00:00:00 CEST al 19 aprile 2012 23:59:60 CEST era attiva la sostituzione: Ad un(a), ad un(a) --> A un(a), a un(a).
- Per le liste generate con la funzione Source:New pages sarebbe auspicabile che gli utenti interessati coordinassero (magari in una pagina all'uopo destinata) le rispettive operazioni al fine di evitare inutili sovrapposizioni. Nel presente contesto che mira a quantificare percentualmente gli errori, può rivelarsi utile specificare, oltre la data, l'orario di formazione della lista come da tabella sottostante.
- AWB dovrebbe essere in grado di elaborare una lista composta da un massimo di 25 000 voci[senza fonte]. [18][19][20]
| Data di calendario | Numero di liste | Numero di voci generate | Numero di voci con errori | Percentuale | Annotazioni |
|---|---|---|---|---|---|
| 3 aprile 2012 | 1 | 2 000 | 235 | 11,75 | |
| 4 aprile 2012 | 1 | 200 | 20 | 10 | |
| 4 aprile 2012 | 1 | 200 | 20 | 10 | |
| 4 aprile 2012 | 1 | 500 | 54 | 10,8 | |
| 5 aprile 2012 | 1 | 800 | 93 | 11,625 | |
| 6 aprile 2012 | 1 | 1 200 | 152 | 12,667 | |
| 7 aprile 2012 14:50 CEST | 1 | 500 | 59 | 11,8 | Source:New pages |
| 7 aprile 2012 | 1 | 500 | 59 | 11,8 | |
| 8 aprile 2012 | 1 | 933 | 183 | 19,614 | Category:Correggere (RecursionDepth:5) |
| 8 aprile 2012 | 1 | 700 | 81 | 11,571 | |
| 9 aprile 2012 | 1 | 1 600 | 195 | 12,188 | |
| 10 aprile 2012 | 1 | 119 | 68 | 57,143 | Category:Passi e valichi della Svizzera (RecursionDepth:5) |
| 11 aprile 2012 14:30 CEST | 1 | 500 | 101 | 20,2 | Source:New pages |
| 11 aprile 2012 | 1 | 500 | 60 | 12 | ora file: 19:33 CEST |
| 12 aprile 2012 | 1 | 1 500 | 175 | 11,667 | |
| 15 aprile 2012 | 1 | 1 200 | 196 | 16,25 | ADD:flashback->flashback; ENABLED:ad un Ad un REPLACED:d cacofonica dove occorre |
| 16 aprile 2012 | 1 | 1 200 | 230 | 19,167 | |
| 17 aprile 2012 14:26 CEST | 1 | 500 | 114 | 22,8 | Source:New pages |
| 18 aprile 2012 | 1 | 582 | 206 | 35,395 | Wiki search:albums (truncated list) |
| 19 aprile 2012 | 1 | 1 050 | 175 | 16,667 | |
| 20 aprile 2012 | 1 | 1 050 | 196 | 18,667 | DISABLED:ad un Ad un |
| 21 aprile 2012 11:38 CEST | 1 | 500 | 78 | 15,6 | Source:New pages |
| 21 aprile 2012 | 1 | 466 | 92 | 19,742 | Category:Videogiochi_sportivi (RecursionDepth:6) |
| 22 aprile 2012 | 1 | 1 500 | 176 | 11,733 | |
| 23 aprile 2012 | 1 | 2 510 | 334 | 13,307 | |
| 24 aprile 2012 | 1 | 900 | 110 | 12,222 | |
| 26 aprile 2012 | 1 | 20 | 18 | 95 | Wiki search:connubbi[21]. |
| 26 aprile 2012 | 1 | 265 | 118 | 44,528 | Wiki search:perchè |
| 27 aprile 2012 13:37 CEST | 1 | 500 | 92 | 18,4 | Source:New pages |
| 30 aprile 2012 | 1 | 4 952 | 1 283 | 25,909 | Category:Categorie_per_personalità (RecursionDepth:6) |
| 1 maggio 2012 | 1 | 1 300 | 240 | 18,462 | |
| 2 maggio 2012 | 1 | 7 552 | 188 | 2,489 | Category:Aiuto |
| 2 maggio 2012 | 1 | 800 | 132 | 16,5 | |
| 4 maggio 2012 | 1 | 1 000 | 177 | 17,7 | |
| 4 maggio 2012 16:25 CEST | 1 | 500 | 61 | 12,2 | Source:New pages |
| 6 maggio 2012 | 1 | 2 386 | 599 | 25,105 | Category:Etica (RecursionDepth:5), (2386 of 3454 articles) |
| 7 maggio 2012 | 1 | 1 600 | 251 | 15,688 | |
| 8 maggio 2012 | >10 | 1 257 | 183 | 14,558 | |
| 10 maggio 2012 | 1 | 1 000 | 150 | 15 | |
| 11 maggio 2012 17:09 CEST | 1 | 500 | 71 | 14,2 | Source:New pages |
| 14 maggio 2012 | 1 | 170 | 89 | 46,471 | Wiki search:22enne |
| riga42 | ? | ||||
| riga43 | ? | ||||
| riga44 | ? | ||||
| riga45 | ? |
(proseguirà...)
Note
- ^ Ultime 1 400 modifiche nella pagina di servizio per l'elaborazione degli errori e il contributo delle utenze partecipanti.
- ^ Caratteristiche delle varie versioni in ordine di uscita
- ^ Una lista contiene, nel presente test, unicamente i soli titoli delle voci formattati, prive dei contenuti i quali vengono caricati in memoria ed elaborati quando in AWB si preme Start.
- ^ Sebbene l'attuale file setting.xml contenga tutte le mie regex e i miei Find and replace ricordo che i Typos esterni caricati in automatico non sono selezionabili (attualmente ammontano a 119 sulla pagina apposita di wikipedia italiana). AWB è perciò un tool ad ampio spettro di correzione (a meno di non disabilitare i Typos esterni e operare col Find and replace del manovratore ridotto al minimo)
- ^ Le correzioni effettivamente salvate sono state 235
- ^ Nella attuale configurazione e in un paio d'anni di uso non ho mai esperito il crash di AWB
- ^ Come "caso limite" mi riferisco alle pagine in NS:0 (giacché il test è circoscritto a questo namespace) che non sono inserite fra gli osservati speciali di nessun utente
- ^ Le altre raccolte di errori sono contenute di default nei file di AWB (in specialissimo modo quelli attinenti alla wiki-formattazione ma non modificabili dall'operatore) e nella pagina dei Typos. Quando AWB attinge a quella pagina scrive nel campo oggetto delle modifiche: , typos fixed:...
- ^ esempi fra i tanti: locuzione "fin da subito" e il punto di vista del prof. Giovanni Nencioni a proposito se si dica terapeuta o terapista?. Non è sufficientemente chiaro cosa abbia da spartire la nascita di una professione con l'etimologia preesistente della parola sulla quale la professione si innesta.
- ^ Accademia della Crusca: D eufonica
- ^ Sulla D eufonica su Wikipedia
- ^ mi riferisco alla versione specializzata messa in opera per essere utilizzata dai dispositivi mobili
- ^ I link esplicativi che, all'interno di una voce, non puntano ad altre voci già presenti su Wikipedia sono in numero talmente elevato da far propendere che coloro che hanno redatto le voci davano per scontato che il termine, nell'eccezione usata, fosse non solo presente in tutti i dizionari inglesi (mica parlo degli italiani nei quali il termine è presente per necessità editoriali), ma fosse entrato nell'uso comune di tutti gli italoparlanti e perciò perfettamente comprensibile. È impossibile elencare tutti i tecnicismi di cui sono infiorettate le voci di sport, musica, spettacolo, tanto per citare quelle fra le più bombardate. In un mio dizionario di inglese (in edizione maggiore di una notissima casa editrice) cheerleader è solo ed esclusivamente quella persona che nei palcoscenici televisivi è incaricata di dare la stura agli applausi. Le cheerleader(s) credevo fossero le "ragazze pon pon" ma qualcuno mi ha fatto notare che non è così... Reunion si traduce con "riunione" (meno male) ma cover oltre che significare "reinterpretazione" assume anche il significato di "custodia, copertina, astuccio" e finalmente mi si dice nella mia pagina utente di non tradurre con reinterpretazione perché cover è voce entrata nell'uso comune. Alla faccia di chi ha scritto la voce cover dove per tre volte si trova il termine "reinterpretazione". Coverizzare sa di studi trascendentali. Vocalist non si traduce con "cantante" perché esegue particolari melodie che lo differenziano (e quali, di grazia, se il redattore ha omesso nel wikitesto italiano la corrispondente aggettivazione inglese?); headliner non si sa cosa sia per cui AWB sa che deve virgolettarlo; la chart è la "classifica", la hit è il "successo", un sold out è un "tutto esaurito", il guitarist è il "chitarrista" l'orgia di diesis (#) non sono delle alterazioni musicali ma significa "numero" (di tipo cardinale) e così via ad libitum oltre ogni dire.
- ^ Mi sono accorto che vi sono utenze che passano il loro tempo a infarcire i testi con "wikilink" verso voci dell'enciclopedia prive di un chiaro nesso logico con l'argomento trattato. Non è detto, non mi pare proprio che il melius abundare quam deficere sia sempre una regola razionale. Una pagina con testo bi-colore (nero e blu) non è il massimo per l'occhio.
- ^ Edit throttle and peak hours. L'articolo parla di limiti per i bot in funzione dell'orario di impiego.
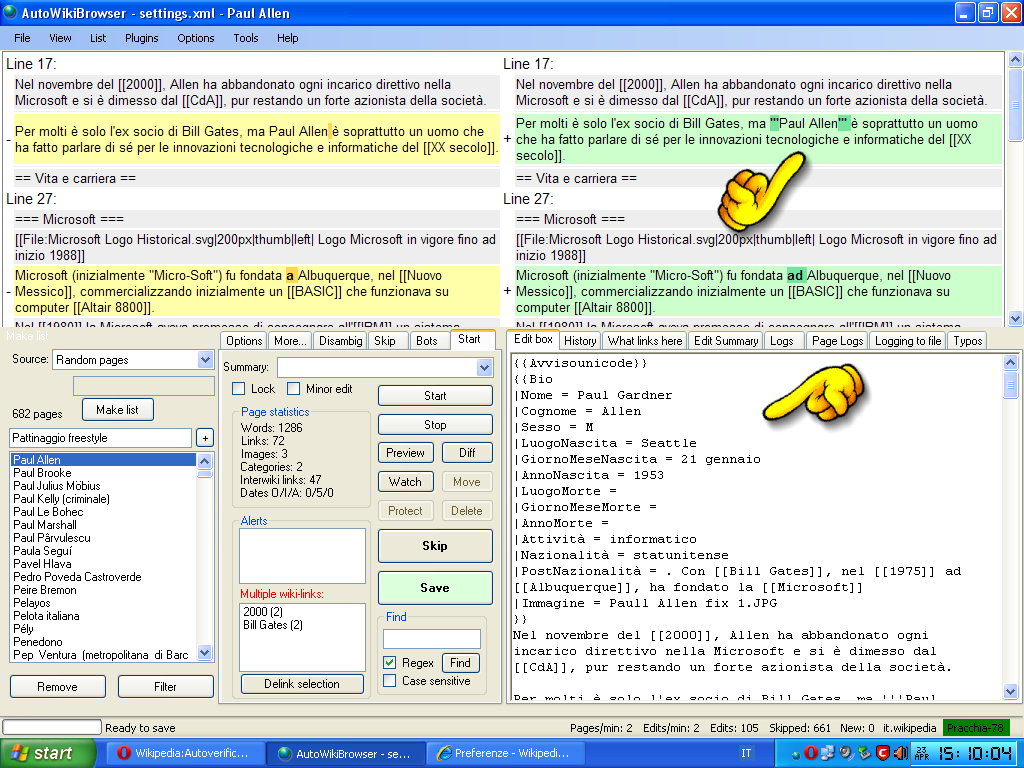
- ^ Immagine esplicativa
- ^ Sezione "spazi nel Manuale di stile
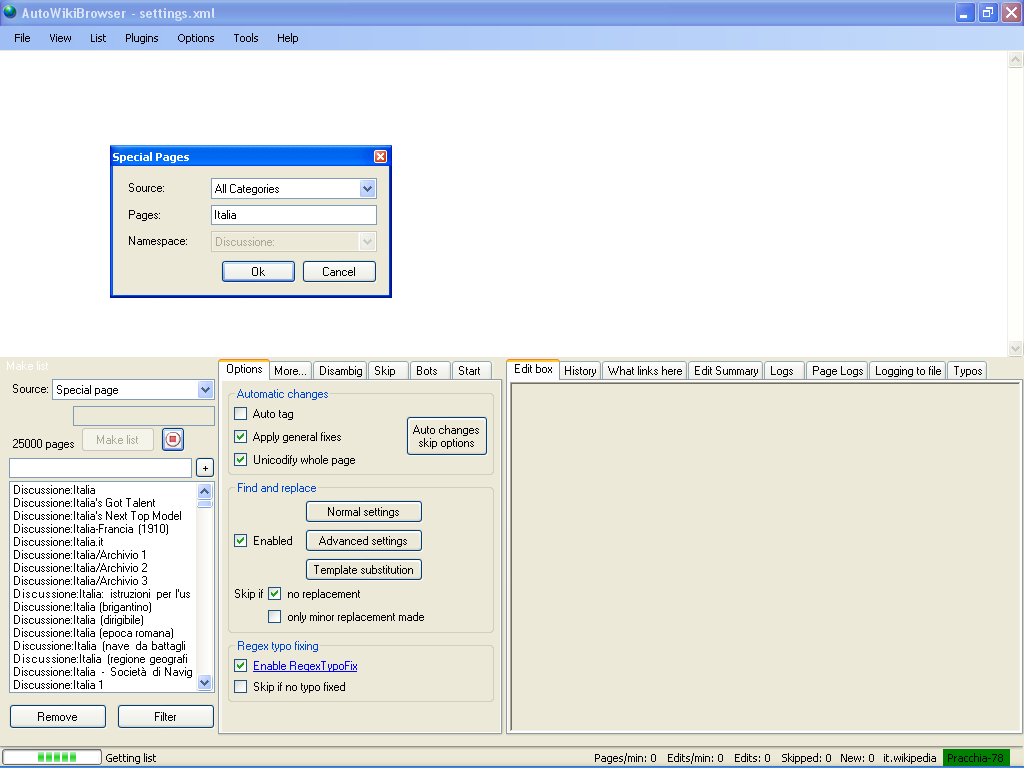
- ^ Attualmente (11 aprile 2012) non posso dimostrare che il valore massimo sia quello indicato in quanto non è riportato nel manuale tecnico. AWB si rifiuta di formare liste contenti oltre 25 000 voci: si veda l'immagine in quanto ho all'attivo un numero di pagine editate una sola volta di molto superiore alle 25 000 voci.
- ^ Un altro esempio che avvalorererebbe il limite massimo di 25 000 voci è la richiesta di una lista sorgente da Special Pages si veda l'immagine dello screenshot.
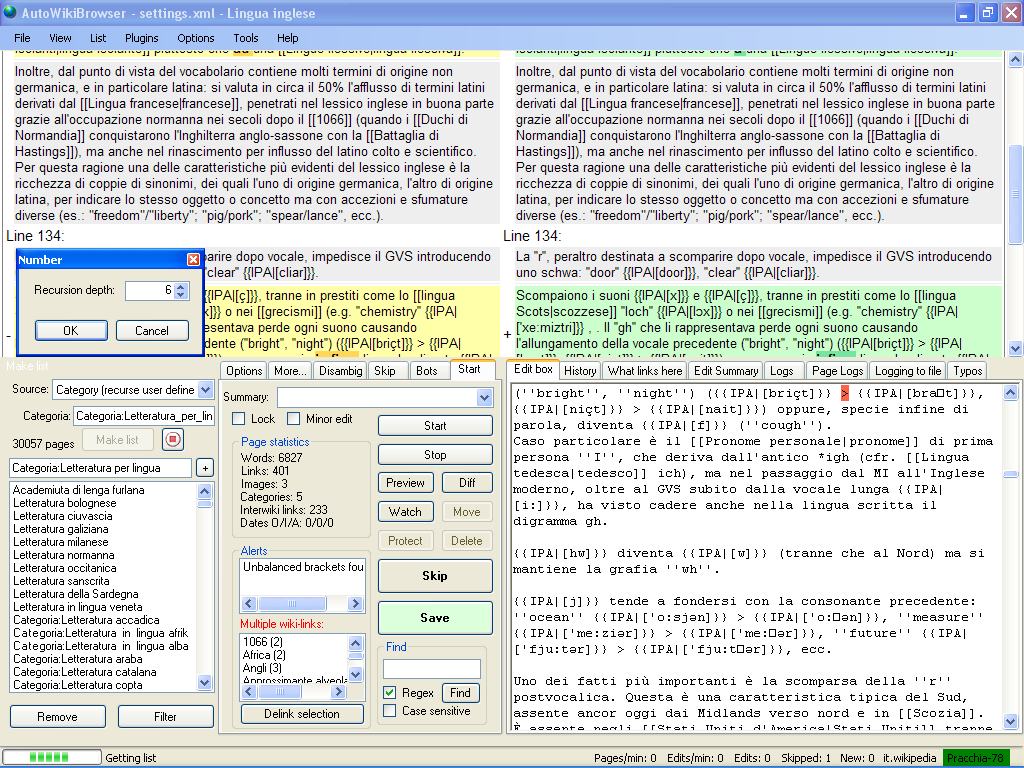
- ^ Avviando la ricerca per la Categoria:Letteratura_per_lingua la lista che si ottiene è composta da 30 507 elementi: una volta richiesto di elencare solo le voci in NS:0 presenti all'interno della lista, queste assommavano a poco più di 19 000
- ^ La ricerca manuale di connubbi dava venti voci. Due sono state ignorate da AWB perché il termine era all'interno del template "Quote" e nell'altro caso l'errore era racchiuso fra le virgolette "connubbio". Se avessi impostato AWB in modalità da scandagliare all'interno delle citazioni, delle note in references ecc. avrei sì trovato tutte le occorrenze di "connubbi*" ma anche ottenuto dei falsi positivi per rimediare ai quali avrei dovuto deselezionarli a mano con conseguente lavoro aggiuntivo (e spreco di tempo). Punteggio di AWB: 18/20.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Voci correlate
Collegamenti esterni
- Dato grezzo di entrata ordinato alfabeticamente. Non è rilevante che sia ordinato ma è utile se volessi cercare più speditamente una determinata voce.
- Dato grezzo di uscita lungo: Text file with annoted wiki markup. Permette di esaminare il lavoro da me svolto nei dettagli, sebbene presenti del testo in esubero rispetto alle normali ed eventuali esigenze di controllo del lavoro.
- Dato grezzo di uscita breve: Text file with wiki markup. È identico a quello presente in questa pagina ma non permette di controllare gl'interventi eseguiti tramite AWB.